小编:当AI计算电源竞争在“系统级别摊牌”期间进入时,建筑革命重建了单卡表演的“摩尔法”神话。美国中国筹码
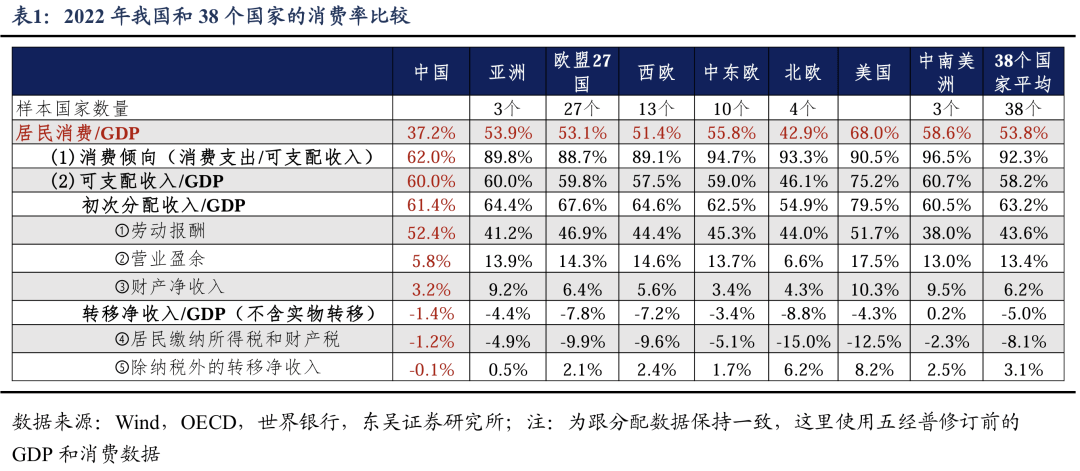
 当AI计算电源竞争在“系统级别摊牌”期间进入时,建筑革命重建了单卡表演的“摩尔法”神话。 Against the ongoing pressure on US chip penalties against China, Huawei climbed to CloudMatrix 384 Supernode to appear, not only exceeded NVIDIA NVL72 flagship with a computing scale of 300pflops, but also declared a way to break the deadlock - using "whole peer architecture" to break power of computing and the use of optical technology in avoiding "memory memory" "Communication Wall". Huang Renxun的焦虑证实了行业的变化:中国的AI计算能力生态系统从“单点突破”转移到“系统维度”“升级”。华为通过不断变化的计算机互动型号的范围较大的范围扩展到了较大的范围,而较大的型号则可以在不断地训练中,从而促进了家庭上升筹码群体的效率。他的意义更深刻在于事实,即由CloudMatrix 384 Supernodes支持的准亿万亿座超教育模式模型训练和DeepSeek推理实践证明,在整个链条中独立地独立于国内计算能力的可能性,并且在整个链中独立进行了传统技术的跨域重复使用,例如《光学通信中国独特的中国独特的路径》在系统变化系统中都有特色。这种“超级节点战”的本质是计算能力范式从upstacking of stacking to tosstection重新定义的硬件的转换。当惩罚迫使Tu的颠覆性Tu对“使用数学来增加物理学”和“使用印地语摩尔来增加摩尔的思维方式”时,全球AI竞争的决定性点已经悄悄地落入了谁可以使用工程工程来弥合单人游戏的生成技术技术,这是中国公司强迫的幸存智慧。当AI计算电源竞争在建筑革命重建了“系统级别摊牌”,即单卡表演的“摩尔法神话”。 Against the ongoing pressure on US chip penalties against China, Huawei climbed to CloudMatrix 384 Supernode to appear, not only exceeded NVIDIA NVL72 flagship with a computing scale of 300pflops, but also declared a way to break the deadlock - using "whole peer architecture" to break Na KapThe power of computing and the use of optical technology to avoid "memory" "Communication Wall". Huang Renxun的焦虑证实了行业的变化:中国的AI计算能力生态系统从“单点突破”转变为“系统维度”“升级”。华为通过通过计算 - 内存互动的巨大范围来推动国内升级筹码群体的效率。培训。由CloudMatrix 384 Supernodes支持的准亿万亿亿MOE模型训练和DeepSeek推理实践证明,在整个链条中都可以独立于国内计算能力,并且在诸如中国对系统变化系统的独特之路等技术的交叉域重复使用方面的优势。这种“超级节点战”的本质是计算能力范式从upstacking of stacking to tosstection重新定义的硬件的转换。当惩罚被迫思考,例如“使用数学来增加物理学”和“使用非摩尔来增加沼泽地”时,全球AI的全球竞争的决定性点已经默默地落在了谁可以使用工程工程来弥合单点生成技术的情况下,这是中国公司的诞生。智慧。扩展全文
Huang Renxun变得越来越关注
任何关注AI行业发展的人都可能会觉得Huan负责NVIDIA的“计算能力帝国”的Grenxun变得越来越焦虑,并开始提及“中国”和“华为”。
“中国做得很好。全世界有50%的人工智能研究人员是中国人。您不能阻止它们,并且您不能阻止他们促进人工智能。如果有人认为这一举动会破坏中国发展人工智能的能力,那么他完全不知道。” Huang Renxun最近在台北计算机展览会上说。
5月19日,NVIDIA首席执行官Huang Renxun在台湾媒体的台北计算机展览照片上发表演讲
今年4月,美国政府对中国Nvidia的筹码H20的“特殊版本”进行了禁令。宣布这一消息后,Huang Renxun立即穿着西装更换了他的皮夹克,然后飞往中国。这是他三个月来中国的第二次。在与政府官员的会议上,黄伦Xun反复强调了中国市场的重要性并表示希望继续与中国合作。
最新的禁令导致NVIDIA预留了Huang Renxun“激烈痛苦”的55亿美元库存损失。
实际上,如果这只是损失十亿美元,那将不是对Nvidia的“损害”。这家市场价值超过3万亿美元的巨人在AI趋势下发了大财。其2025财政年度的收入达到1305亿美元,每年增长114%;它的净利润达到729亿美元,同比增长145%;它的毛利润率达到了惊人的75%。
塔拉尔·纳克森(Huang Renxun)的塔拉尔(Larremermement)是,在美国禁令的压力下,中国的独立技术正在迅速破坏。在NVIDIA的关键护城河中,不仅硬件(例如GPU),还可以并行计算平台和编程模型以及高速互连技术NVLINK。在单点比赛中,中国公司可能很难动摇NVIDIA的立场,但是系统竞争不需要。
最近,华为详细介绍了Ascend CloudMatrix 384超级节点技术。该技术使用国内升芯片,并且在主要维度(例如计算功率量表,培训和推动效率和可靠性)等主要方面超过了NVL72的NVL72系统。其中的主要部分是华为摧毁了单卡计算能力的竞争,并通过与计算,存储,网络和体系结构中的创新思想进行协作,它包括硬件和芯片流程的局限性,并扩大芯片和系统功能。
Huang Renxun最关心建立替代Nvidia的计划。这不仅可能导致中国永久损失,而且其“计算帝国”的统治基础也可以动摇。他打电话给美国政府:只有通过开发人员的获胜平台,我们才能赢得胜利,而出口控制措施才能加强美国平台,而不是强迫一半的AI人才在Wor中LD与竞争对手一起流动。
看到中国再次取得成功,美国政客们真的很担心,但他们显然忽略了黄伦Xun呼吁放松法规的呼吁。尽管NVIDIA对中国的出口紧密,但美国商业部门最近试图抑制华为在世界各地攀登筹码,并迫使EDA巨人切断了中国的供应。但是正如黄伦Xun所说,它只会激发中国企业生活的能力。
直到今年4月,美国切断了中国的H20供应,华为云才领导CloudMatrix 384超级节点商业化,然后在Gui'an和Rulaqab商业上使用它。内部人士称其为“核泵水平”。今年上半年将推出数千张卡片,目的是“完全焦虑地计算该行业”。最近,华为重新宣布,它已成功地在Ascend Platform上成功地完成了对Moe的准亿万型型号的全面处理的培训,并在集群培训系统的表现上实现了领导,进一步证明了改变国内AI基础设施的独立能力。
资料来源:observer.com
"Four years ago, the Nvidia market sharing in China was as high as 95%, but now it's only 50%. If we are not competing in China, we will allow China to develop new platforms and build a rich ecosystem, and they are not from the United States, when promoting artificial technology of intelligence in the world, their technology and leadership are spreading throughout the world's technology, their technology and leadership of all the world's technology, their technology and the leadership of all the world's technology, their technology领导者世界。
现在更有趣的是华为如何使用超级n没有高级过程的马兰布尔登·恩维迪亚(Malamburden Nvidia)?
华为创建了“计算电力核弹”
电影“ Sky Bugid”中有一个剪辑,西北核基地的总指挥官冯施与从国外返回的专家Lu Guangda聊天,再到戈比沙漠。冯史在他多年前的经验中说:“在韩国战场上,我们得到了一个美国军事俘虏和一个小公司。他在我面前非常努力地关心,扔了一个原子炸弹来品尝并与我们进行行动。”
“武器是向后的,所以我们很生气。但是,尽管如此,我们放弃了吗?”冯施兴奋地说。
当时,苏联突然中断了该协议,没有警告,并删除了提供技术援助的所有专家,而美国则强加了技术性的中国。电影屏幕显示,在没有计算机支持的情况下,我们的专家决定采用海鲜战术,通过日夜制定计划,他们有FinaLly计算了一年以上的答案,以帮助开发原子弹。
从“天上”的静止
60年过去了,美国仍在试图通过技术封锁来阻止中国人工智能行业的发展,这确实给中国计算中国带来了焦虑。毕竟,大型模型的缩放定律仍然有效。参数和数据越多,它可以携带的性能和智力越强,这不可避免地会导致对计算强度,视频记忆和带宽需求的增加。
但是,即使无法陷入芯片制造过程,中国也不是无助的。随着模型变得越来越大,单卡计算能力的优势相对较弱,集群和系统的计算能力解决方案是一般趋势,这是中国的挑战和机会。
在压力惩罚下,华为的技术群体建议了基本ideas such as "use of math to increase physics", "non Moore's law to increase Moore Law", and "using systems to increase single points": Based on the actual available chip-making process, calculated and storage to store technology of storing and storing technology and storing technology and storing technology and networking technology has been stored network storage technology Modern, create an architecture of computing, and create a "super node + cluster" system computing power solution to continue to meet the demands of computing strength in长期以来,在2022年下半年,“在风暴中”的华为已经启动了超级节点研发,并且该项目参与了许多业务团队,例如Hisilicon,Computing和Clouds。项目团队的一位专家回忆说,当时的64张卡解决方案已经足够了,但是华为的目标是计划未来,并准备通过攀登AI Cloud Service来赋予行业中的计算能力,该服务可以分开或结合超节点计算的功率。如果更大的话,那会很好,但是如果较小,那就很好。在内部讨论之后,华为决定投资384个超级节点研发。
严格来说,SuperPod并不是一个新概念,像Google和Nvidia这样的巨人已经探索了很长时间。技术的背景是当大型神经网络模型(例如变压器出现,计算强度和视频记忆的需求增长)以及单个GPU甚至单个服务器都难以预防时。目前,有必要生产大量高速计算芯片(即超级节点)的完善结构。与传统的计算群集相比,超节点不仅需要组装大量GPU的计算强度,而且还需要开发出极高的速度,而GPU和服务器之间相互关联以减少计算PAR的开销Allel。通过合并大量的GPU,它们提供了AI计算的重要有效能力,并共同执行培训和识别任务。
上一年的3月,NVIDIA推出了GB200 NVL72超级节点。 Nvidia用“内部高速专用线” NVLink紧密结合了36个Grace CPU和72个Blackwell GPU,以产生逻辑上的“巨型GPU”。计算量表达到了180个频率,网络互连的总带宽达到130TB/s,总存储器带宽达到576TB/s。根据NVIDIA的说法,GB200 NVL72超节点可以将大型模型的数万亿参数速度提高30倍。
中国也有许多探索超节点技术的公司。例如,由百度kunlun核心构建的超节点,通过自开发的互连通信协议XPU链接,单个机柜可以容纳32/64 Kunlun Core AI加速卡,而单个机柜中的卡片可以实现完整的CONTACT,带宽的增加高达8次。机柜计算的强度可以达到传统形式的8 8卡服务器。此外,诸如阿里巴巴,腾讯和中国手机等巨头还与许多软件和硬件公司联手启动了各种超级节点互连的开放标准。
但是目前,华为是唯一可以使用国家芯片生产超级节点并在各个方面都可以超越NVL72的人。 Ascend CloudMatrix 384超节点连接到高速互连总线,由12个计算柜和4个总线柜组成。目前,它是该行业中最大的超级节点。计算强度的总尺度达到了300pflops,即NVIDIA NVL72的1.7倍;网络互连的总带宽达到269TB/s,比NVIDIA NVL72增加了107%;记忆的总带宽达到1229TB/s,超过NVIDIA NVL72增加了113%。更重要的是,通过最佳L网络平衡和其他解决方案的弹奏,Astend SuperNode可以进一步扩展,其中包含数千张卡的Atlas 900 SuperNode SuperNode,可以支持该模型未来模型的更大尺寸演变。
升天云Matrix 384超节点结构
Ascend CloudMatrix 384 Super节点是华为在重压下造成的“计算功率核弹”。但是,与NVIDIA和ASTON计划相比,有几个问题是不可避免的。华为是否仅通过退出更多卡就超过了Nvidia? Nvidia和其他公司为什么不堆更多的卡?与将ANG卡放入机柜中的NVIDIA(更传统的超级节点,扩展)相比,为什么可以将ASENT分为许多计算柜(扩展)?通过开发这样的巨型计算电源系统可以解决什么问题?
从座位芯片到装配体系结构
超节点是华为的突破和不可避免的行业发展。
面对专业大型模型缩放定律带来的计算强度需求,传统解决方案是尽可能多的堆栈卡,并发展出更大的计算强度群。但是,问题在于,无限的堆栈卡可能不会为计算能力带来线性改进,而是带来诸如“墙壁内存”,“比例墙”和“通信墙”之类的问题。在计算集群中,如果TheGPU和服务器无法“有效地交谈”,则GPU将会闲置,因为没有足够的数据来计算,这将导致1+12结果。
在过去的8年中,单卡的计算强度增加了40倍,但是节点上的公共汽车频段仅增加了9次,并且整个节点的网络带宽仅增加了4倍,这使得群集网络通信成为当前主要培训和理解的最大挑战。因此,如果沟通效率无法提高,则只有384张上升卡将不超过72 NVIDI卡片和服务器之间通信的开销将破坏计算能力的增加,从而导致计算能力的有效力量不会上升而是下降。
特别是,由于MoE(混合专家模型)是EatenDeepSeek成为主要模型的结构,因此这种混合并行性的复杂方法带来了巨大的挑战,并且沟通需求急剧增加,而单一的TP流量(男高音张量),Sp。实用数据表明,当TP,SP或EP等共享技术的并行域中的混合域超过8张卡时,跨机器通信带宽成为性能瓶颈,从而导致系统性能的显着下降。
在这个行业的过程中,NVLink具有更多的价值。它的重要性在于在GPU之间形成了“超宽车道”,从而使GPU错过了CPU直接通信。基于此,NVIDIA完全集成了许多GPU,CPU,高速内存,NVLINK/NVSWITCH等产生NVL72超级节点。但是问题在于,NVLink只是其自己的GPU之间的通信协议,还包括非GPU异质硬件节点(如NPU和FPGA)无法通过NVLink等专用线路进行通信,并且仍然必须通过较低效率的PCIE协议进行GPU过境。节点之间的以太网/Infiniband交叉计算机的相干性在大规模计算中还具有带宽瓶颈。
与NVIDIA的修补改进相比,攀登CloudMatrix 384超级节点选择重塑传统的计算体系结构。这个基本的基本在于完全违反了以CPU为中心的冯·诺伊曼(Von Neumann)的传统建筑,即“奴隶建筑”,而创新的则暗示了“ bpeer架构”。随着高速互连总线的主要成功,总线从服务器扩展到整个机柜,甚至在机柜中,最终与合并的来源相互关联例如CPU,NPU,DPU,存储和内存。达到更高的计算强度密度和互连的带宽。
资料来源:observer.com
“过去,数据中心是由CPU安排的。AscendCloudMatrix 384的主要概念是点对点和交流点对点体系结构,而无需超越第三方交流。”华为专家告诉Observer.com,在超节点范围内,高速总线互连用于替换传统的以太网,并且通信的带宽是提高了15次。单跳通信延迟也从2微秒到200纳秒(降低10倍)实现。借助“ AI独家高架桥”,群集可以像计算机一样运行,从而打破了性能限制。
Ascend CloudMatrix 384超节点可以提高通信效率的另一个主要原因是它使用光通信技术。在Ascend CloudMatrix 384超级节点中,总共3,168 OPT使用ICAL纤维和6,912 400G光学模块。相比之下,NVIDIA NVL72超节点采用了完整的铜线建筑,其成本低和消耗。部署时,它保持整洁且相对稳定。但是,缺点是它只能在2米内部署,否则通信率将被高度封闭,因此可以连接的芯片数量受到限制。光学模块具有高带宽和高速,低损失的好处,适合长期交付,因此它们可以连接到更多的芯片并变得灵活地扩展。
但是,光学通信并非全部有用。光学模块的成本是铜线的两倍,并且电力消耗大大增加。光纤非常脆弱,故障率很高。插座未紧密插入,纤维弯曲,插头为灰色。任何小问题都可以断开连接。因此,尽管Nvidia考虑使用光学该模块将在2022年连接256 H100,最终评估了成本和稳定性,并决定不将其投入劳动。为了空白,光学通信技术很难控制。
但是对于像华为这样的巨型通信,“光学模块都不好”。长期以来积累的光学通信技术已经取得了国际领导,而是与超节点通信相比,发展了独特的优势。此外,鉴于超频群集容易发生故障的属性,华为云还配备了带有一般从业者 - 安丝斯德云脑的超级节点,该云主要包括“ 1-3-10”。步骤2:请确保找到问题3分钟并找到根本原因;步骤3:在10分钟内恢复,快速调整或保持系统运行。
国内计算能力还可以产生顶级大型模型
Ascend CloudMatrix 384 Super Node的缝线在出现之前吸引了很多关注中国。
一家著名的海外审查机构半分析在一份报告中教导说,华为芯片是其背后的一代,但其扩展解决方案是导致当前NVIDIA和AMD产品的一代。在上升芯片中开发的华为云云384超节点可以直接与NVL72的NVL72竞争,并且比NVIDIA机架级解决方案对某些指标更为先进。它的工程优势可以在涵盖网络,光学通信和软件的系统级别上看到。
甚至黄伦Xun也承认,他被华为超过了他:“从技术参数来看,华为的CloudMatrix 384 SuperNode甚至超过了Nvidia的性能,具有比Nvidia的TechnologyTol的优势。布局非常远,并且是绝对正确的战略方向。
TechInsights关于CloudMatrix 384 Hyprove Nabode的报告
在认识最强大的对手的背后,只有华为才能理解破坏的困难。一个华为云的IDER表明,没有早期的光学模块。我想使用“非摩尔来解决摩尔法律”,但是摩尔的问题更大。 “我们只能为每个光学模块的面部所有末端拍照并单独研究它们,并解决无数问题以实现更好的稳定性。”
勤奋的工作付费。 Ascend CloudMatrix 384超级节点的出现带来了国内行业的第二选择。
我相信每个人仍然会记得DeepSeek在今年年初的受欢迎程度。当时,华为云和基于硅的流动性将DeepSeekr1/V3共同部署到CloudMatrix 384 SuperNode,达到了与NVIDIA H100相当的效果,甚至提供了保护水平。首先,DeepSeek是Moe模型。与传统的密集模型相比,它只会调用一些最适合当前任务参与工作的专业节点G计算和提高理解速度的力量。同时,Ascend CloudMatrix 384超级节点具有“ Demaster-Slave,整个对等”计算功率体系结构,这与MOE模型自然相关。与许多具有卡的专家的传统“小型车间”模型相比,超级节点类似于“大型工厂模型”。通过高速互连总线,可以进行ICARD和专家的分布式识别,并且单个卡的MOE计算和通信效率的效率得到了极大提高。
几年前,当我们设计超节点时,每个人都认为这是巨大的,因为加载是持续的交替技术,更改模型和硬件更改。当时,CloudMatrix 384超级节点的大小很大。即使在今天,还有256位DeepSeek专家可以在这里实现一张卡和专家,同时部署了更多多余的专家。虽然人口最多AR模型,我们足以支持它。华为专家在Observer.com上说。
华为开发巨型计算电源系统的目的不仅仅是推理。过去,像DeepSeek和Qwen这样的整个Chithat的大型模型主要受到NVIDIA平台的培训。最近,华为发布了一种新型号,其大小参数高达7180亿,即Pangu Ultra Moe,该模型是在整个过程中在Ascend AI计算平台上训练的准亿万个MOE的模型。在培训方法方面,华为首次揭示了MOE增强学习(RL)在Ascend CloudMatrix 384 Super Node中训练后训练框架的关键技术,从而使R-R训练在多余的节点群集过程中输入。
从Pangu Pro“ Fighting Small”到一流的准三算工业718B(Pangu ultra Moe),经常刷新预防速度记录,Huawei成功地完成了完整的InpertionD.动力型电源型模型的ENT和受控培训。 “
电力消耗是一个问题,但不是限制
当然,超级节点的本质仍在堆栈卡上。这种“暴力奇迹”模型将不可避免地带来诸如电力消耗和冷却之类的困难。传统服务器机柜的电力消耗通常是几千瓦的,并且AI超级节点柜的电力消耗可以达到100千瓦或更高。在超过NVL72的同时,Astron CloudMatrix 384超节点也消耗了后者的4.1倍,并且每次翻牌的功耗高2.5倍。
但是,应该指出的是,即使电力消耗是一个在中国不容忽视的问题,但它并不是一个严格的因素。半分析指出,该报告通常被认为是仅限于西方电力的人造凯特瑟(Kateither),但中国的情况恰恰相反。在除热力外,中国还拥有太阳能,水力发电和风强度的最大装机能力,目前处于领先的核电扩展位置。如果由于相对足够的强度而导致无限的电力消耗,则离开电力消耗指数并提高可扩展性是有意义的。
华为并非完全没有仔细的电力消耗。 Observer.com上的华为技术专家表示,华为拥有许多独特的液体冷却技术,包括创新的工程,例如三明治建筑,空气冷却还具有许多现代工程和技术,可确保控制和减少电力消耗。同时,无论是多余的节点还是脱毛群,它并不总是充满负载。华为还产生了一些动态的频率和冷却法规。
在云计算中心,华为云还建立了一个恒定的“训练基础”温度并使用液态冷板耗散耗散技术,使制冷剂可以直接接触并反映比传统空气冷却高50%的热量散热。此外,ICooling智能温度控制系统每五分钟都会动态调整该方法,无论外部温度变化多少,数据中心都可以保持在最佳状态。最终,与PUE相比,数据中心的能源效率为1.12,比该行业的平均值占能源节省的70%。
实际上,在技术封锁下,毫无疑问,Tagumpay以最大的成本解决了真正的问题。华为的想法也转化了空间计算的强度,带宽计算能力和能量计算的强度。当单点技术被阻止时,整个合作和量表的优势将是破坏僵局的关键。在更复杂的国际环境中,华为的诞生爬上CloudMatrix 384超级节点不仅为国家提供了第二种选择,而且还为AI的AI行业提供了“安心”。
回到Sohu看看更多
当AI计算电源竞争在“系统级别摊牌”期间进入时,建筑革命重建了单卡表演的“摩尔法”神话。 Against the ongoing pressure on US chip penalties against China, Huawei climbed to CloudMatrix 384 Supernode to appear, not only exceeded NVIDIA NVL72 flagship with a computing scale of 300pflops, but also declared a way to break the deadlock - using "whole peer architecture" to break power of computing and the use of optical technology in avoiding "memory memory" "Communication Wall". Huang Renxun的焦虑证实了行业的变化:中国的AI计算能力生态系统从“单点突破”转移到“系统维度”“升级”。华为通过不断变化的计算机互动型号的范围较大的范围扩展到了较大的范围,而较大的型号则可以在不断地训练中,从而促进了家庭上升筹码群体的效率。他的意义更深刻在于事实,即由CloudMatrix 384 Supernodes支持的准亿万亿座超教育模式模型训练和DeepSeek推理实践证明,在整个链条中独立地独立于国内计算能力的可能性,并且在整个链中独立进行了传统技术的跨域重复使用,例如《光学通信中国独特的中国独特的路径》在系统变化系统中都有特色。这种“超级节点战”的本质是计算能力范式从upstacking of stacking to tosstection重新定义的硬件的转换。当惩罚迫使Tu的颠覆性Tu对“使用数学来增加物理学”和“使用印地语摩尔来增加摩尔的思维方式”时,全球AI竞争的决定性点已经悄悄地落入了谁可以使用工程工程来弥合单人游戏的生成技术技术,这是中国公司强迫的幸存智慧。当AI计算电源竞争在建筑革命重建了“系统级别摊牌”,即单卡表演的“摩尔法神话”。 Against the ongoing pressure on US chip penalties against China, Huawei climbed to CloudMatrix 384 Supernode to appear, not only exceeded NVIDIA NVL72 flagship with a computing scale of 300pflops, but also declared a way to break the deadlock - using "whole peer architecture" to break Na KapThe power of computing and the use of optical technology to avoid "memory" "Communication Wall". Huang Renxun的焦虑证实了行业的变化:中国的AI计算能力生态系统从“单点突破”转变为“系统维度”“升级”。华为通过通过计算 - 内存互动的巨大范围来推动国内升级筹码群体的效率。培训。由CloudMatrix 384 Supernodes支持的准亿万亿亿MOE模型训练和DeepSeek推理实践证明,在整个链条中都可以独立于国内计算能力,并且在诸如中国对系统变化系统的独特之路等技术的交叉域重复使用方面的优势。这种“超级节点战”的本质是计算能力范式从upstacking of stacking to tosstection重新定义的硬件的转换。当惩罚被迫思考,例如“使用数学来增加物理学”和“使用非摩尔来增加沼泽地”时,全球AI的全球竞争的决定性点已经默默地落在了谁可以使用工程工程来弥合单点生成技术的情况下,这是中国公司的诞生。智慧。扩展全文
Huang Renxun变得越来越关注
任何关注AI行业发展的人都可能会觉得Huan负责NVIDIA的“计算能力帝国”的Grenxun变得越来越焦虑,并开始提及“中国”和“华为”。
“中国做得很好。全世界有50%的人工智能研究人员是中国人。您不能阻止它们,并且您不能阻止他们促进人工智能。如果有人认为这一举动会破坏中国发展人工智能的能力,那么他完全不知道。” Huang Renxun最近在台北计算机展览会上说。
5月19日,NVIDIA首席执行官Huang Renxun在台湾媒体的台北计算机展览照片上发表演讲
今年4月,美国政府对中国Nvidia的筹码H20的“特殊版本”进行了禁令。宣布这一消息后,Huang Renxun立即穿着西装更换了他的皮夹克,然后飞往中国。这是他三个月来中国的第二次。在与政府官员的会议上,黄伦Xun反复强调了中国市场的重要性并表示希望继续与中国合作。
最新的禁令导致NVIDIA预留了Huang Renxun“激烈痛苦”的55亿美元库存损失。
实际上,如果这只是损失十亿美元,那将不是对Nvidia的“损害”。这家市场价值超过3万亿美元的巨人在AI趋势下发了大财。其2025财政年度的收入达到1305亿美元,每年增长114%;它的净利润达到729亿美元,同比增长145%;它的毛利润率达到了惊人的75%。
塔拉尔·纳克森(Huang Renxun)的塔拉尔(Larremermement)是,在美国禁令的压力下,中国的独立技术正在迅速破坏。在NVIDIA的关键护城河中,不仅硬件(例如GPU),还可以并行计算平台和编程模型以及高速互连技术NVLINK。在单点比赛中,中国公司可能很难动摇NVIDIA的立场,但是系统竞争不需要。
最近,华为详细介绍了Ascend CloudMatrix 384超级节点技术。该技术使用国内升芯片,并且在主要维度(例如计算功率量表,培训和推动效率和可靠性)等主要方面超过了NVL72的NVL72系统。其中的主要部分是华为摧毁了单卡计算能力的竞争,并通过与计算,存储,网络和体系结构中的创新思想进行协作,它包括硬件和芯片流程的局限性,并扩大芯片和系统功能。
Huang Renxun最关心建立替代Nvidia的计划。这不仅可能导致中国永久损失,而且其“计算帝国”的统治基础也可以动摇。他打电话给美国政府:只有通过开发人员的获胜平台,我们才能赢得胜利,而出口控制措施才能加强美国平台,而不是强迫一半的AI人才在Wor中LD与竞争对手一起流动。
看到中国再次取得成功,美国政客们真的很担心,但他们显然忽略了黄伦Xun呼吁放松法规的呼吁。尽管NVIDIA对中国的出口紧密,但美国商业部门最近试图抑制华为在世界各地攀登筹码,并迫使EDA巨人切断了中国的供应。但是正如黄伦Xun所说,它只会激发中国企业生活的能力。
直到今年4月,美国切断了中国的H20供应,华为云才领导CloudMatrix 384超级节点商业化,然后在Gui'an和Rulaqab商业上使用它。内部人士称其为“核泵水平”。今年上半年将推出数千张卡片,目的是“完全焦虑地计算该行业”。最近,华为重新宣布,它已成功地在Ascend Platform上成功地完成了对Moe的准亿万型型号的全面处理的培训,并在集群培训系统的表现上实现了领导,进一步证明了改变国内AI基础设施的独立能力。
资料来源:observer.com
"Four years ago, the Nvidia market sharing in China was as high as 95%, but now it's only 50%. If we are not competing in China, we will allow China to develop new platforms and build a rich ecosystem, and they are not from the United States, when promoting artificial technology of intelligence in the world, their technology and leadership are spreading throughout the world's technology, their technology and leadership of all the world's technology, their technology and the leadership of all the world's technology, their technology领导者世界。
现在更有趣的是华为如何使用超级n没有高级过程的马兰布尔登·恩维迪亚(Malamburden Nvidia)?
华为创建了“计算电力核弹”
电影“ Sky Bugid”中有一个剪辑,西北核基地的总指挥官冯施与从国外返回的专家Lu Guangda聊天,再到戈比沙漠。冯史在他多年前的经验中说:“在韩国战场上,我们得到了一个美国军事俘虏和一个小公司。他在我面前非常努力地关心,扔了一个原子炸弹来品尝并与我们进行行动。”
“武器是向后的,所以我们很生气。但是,尽管如此,我们放弃了吗?”冯施兴奋地说。
当时,苏联突然中断了该协议,没有警告,并删除了提供技术援助的所有专家,而美国则强加了技术性的中国。电影屏幕显示,在没有计算机支持的情况下,我们的专家决定采用海鲜战术,通过日夜制定计划,他们有FinaLly计算了一年以上的答案,以帮助开发原子弹。
从“天上”的静止
60年过去了,美国仍在试图通过技术封锁来阻止中国人工智能行业的发展,这确实给中国计算中国带来了焦虑。毕竟,大型模型的缩放定律仍然有效。参数和数据越多,它可以携带的性能和智力越强,这不可避免地会导致对计算强度,视频记忆和带宽需求的增加。
但是,即使无法陷入芯片制造过程,中国也不是无助的。随着模型变得越来越大,单卡计算能力的优势相对较弱,集群和系统的计算能力解决方案是一般趋势,这是中国的挑战和机会。
在压力惩罚下,华为的技术群体建议了基本ideas such as "use of math to increase physics", "non Moore's law to increase Moore Law", and "using systems to increase single points": Based on the actual available chip-making process, calculated and storage to store technology of storing and storing technology and storing technology and storing technology and networking technology has been stored network storage technology Modern, create an architecture of computing, and create a "super node + cluster" system computing power solution to continue to meet the demands of computing strength in长期以来,在2022年下半年,“在风暴中”的华为已经启动了超级节点研发,并且该项目参与了许多业务团队,例如Hisilicon,Computing和Clouds。项目团队的一位专家回忆说,当时的64张卡解决方案已经足够了,但是华为的目标是计划未来,并准备通过攀登AI Cloud Service来赋予行业中的计算能力,该服务可以分开或结合超节点计算的功率。如果更大的话,那会很好,但是如果较小,那就很好。在内部讨论之后,华为决定投资384个超级节点研发。
严格来说,SuperPod并不是一个新概念,像Google和Nvidia这样的巨人已经探索了很长时间。技术的背景是当大型神经网络模型(例如变压器出现,计算强度和视频记忆的需求增长)以及单个GPU甚至单个服务器都难以预防时。目前,有必要生产大量高速计算芯片(即超级节点)的完善结构。与传统的计算群集相比,超节点不仅需要组装大量GPU的计算强度,而且还需要开发出极高的速度,而GPU和服务器之间相互关联以减少计算PAR的开销Allel。通过合并大量的GPU,它们提供了AI计算的重要有效能力,并共同执行培训和识别任务。
上一年的3月,NVIDIA推出了GB200 NVL72超级节点。 Nvidia用“内部高速专用线” NVLink紧密结合了36个Grace CPU和72个Blackwell GPU,以产生逻辑上的“巨型GPU”。计算量表达到了180个频率,网络互连的总带宽达到130TB/s,总存储器带宽达到576TB/s。根据NVIDIA的说法,GB200 NVL72超节点可以将大型模型的数万亿参数速度提高30倍。
中国也有许多探索超节点技术的公司。例如,由百度kunlun核心构建的超节点,通过自开发的互连通信协议XPU链接,单个机柜可以容纳32/64 Kunlun Core AI加速卡,而单个机柜中的卡片可以实现完整的CONTACT,带宽的增加高达8次。机柜计算的强度可以达到传统形式的8 8卡服务器。此外,诸如阿里巴巴,腾讯和中国手机等巨头还与许多软件和硬件公司联手启动了各种超级节点互连的开放标准。
但是目前,华为是唯一可以使用国家芯片生产超级节点并在各个方面都可以超越NVL72的人。 Ascend CloudMatrix 384超节点连接到高速互连总线,由12个计算柜和4个总线柜组成。目前,它是该行业中最大的超级节点。计算强度的总尺度达到了300pflops,即NVIDIA NVL72的1.7倍;网络互连的总带宽达到269TB/s,比NVIDIA NVL72增加了107%;记忆的总带宽达到1229TB/s,超过NVIDIA NVL72增加了113%。更重要的是,通过最佳L网络平衡和其他解决方案的弹奏,Astend SuperNode可以进一步扩展,其中包含数千张卡的Atlas 900 SuperNode SuperNode,可以支持该模型未来模型的更大尺寸演变。
升天云Matrix 384超节点结构
Ascend CloudMatrix 384 Super节点是华为在重压下造成的“计算功率核弹”。但是,与NVIDIA和ASTON计划相比,有几个问题是不可避免的。华为是否仅通过退出更多卡就超过了Nvidia? Nvidia和其他公司为什么不堆更多的卡?与将ANG卡放入机柜中的NVIDIA(更传统的超级节点,扩展)相比,为什么可以将ASENT分为许多计算柜(扩展)?通过开发这样的巨型计算电源系统可以解决什么问题?
从座位芯片到装配体系结构
超节点是华为的突破和不可避免的行业发展。
面对专业大型模型缩放定律带来的计算强度需求,传统解决方案是尽可能多的堆栈卡,并发展出更大的计算强度群。但是,问题在于,无限的堆栈卡可能不会为计算能力带来线性改进,而是带来诸如“墙壁内存”,“比例墙”和“通信墙”之类的问题。在计算集群中,如果TheGPU和服务器无法“有效地交谈”,则GPU将会闲置,因为没有足够的数据来计算,这将导致1+12结果。
在过去的8年中,单卡的计算强度增加了40倍,但是节点上的公共汽车频段仅增加了9次,并且整个节点的网络带宽仅增加了4倍,这使得群集网络通信成为当前主要培训和理解的最大挑战。因此,如果沟通效率无法提高,则只有384张上升卡将不超过72 NVIDI卡片和服务器之间通信的开销将破坏计算能力的增加,从而导致计算能力的有效力量不会上升而是下降。
特别是,由于MoE(混合专家模型)是EatenDeepSeek成为主要模型的结构,因此这种混合并行性的复杂方法带来了巨大的挑战,并且沟通需求急剧增加,而单一的TP流量(男高音张量),Sp。实用数据表明,当TP,SP或EP等共享技术的并行域中的混合域超过8张卡时,跨机器通信带宽成为性能瓶颈,从而导致系统性能的显着下降。
在这个行业的过程中,NVLink具有更多的价值。它的重要性在于在GPU之间形成了“超宽车道”,从而使GPU错过了CPU直接通信。基于此,NVIDIA完全集成了许多GPU,CPU,高速内存,NVLINK/NVSWITCH等产生NVL72超级节点。但是问题在于,NVLink只是其自己的GPU之间的通信协议,还包括非GPU异质硬件节点(如NPU和FPGA)无法通过NVLink等专用线路进行通信,并且仍然必须通过较低效率的PCIE协议进行GPU过境。节点之间的以太网/Infiniband交叉计算机的相干性在大规模计算中还具有带宽瓶颈。
与NVIDIA的修补改进相比,攀登CloudMatrix 384超级节点选择重塑传统的计算体系结构。这个基本的基本在于完全违反了以CPU为中心的冯·诺伊曼(Von Neumann)的传统建筑,即“奴隶建筑”,而创新的则暗示了“ bpeer架构”。随着高速互连总线的主要成功,总线从服务器扩展到整个机柜,甚至在机柜中,最终与合并的来源相互关联例如CPU,NPU,DPU,存储和内存。达到更高的计算强度密度和互连的带宽。
资料来源:observer.com
“过去,数据中心是由CPU安排的。AscendCloudMatrix 384的主要概念是点对点和交流点对点体系结构,而无需超越第三方交流。”华为专家告诉Observer.com,在超节点范围内,高速总线互连用于替换传统的以太网,并且通信的带宽是提高了15次。单跳通信延迟也从2微秒到200纳秒(降低10倍)实现。借助“ AI独家高架桥”,群集可以像计算机一样运行,从而打破了性能限制。
Ascend CloudMatrix 384超节点可以提高通信效率的另一个主要原因是它使用光通信技术。在Ascend CloudMatrix 384超级节点中,总共3,168 OPT使用ICAL纤维和6,912 400G光学模块。相比之下,NVIDIA NVL72超节点采用了完整的铜线建筑,其成本低和消耗。部署时,它保持整洁且相对稳定。但是,缺点是它只能在2米内部署,否则通信率将被高度封闭,因此可以连接的芯片数量受到限制。光学模块具有高带宽和高速,低损失的好处,适合长期交付,因此它们可以连接到更多的芯片并变得灵活地扩展。
但是,光学通信并非全部有用。光学模块的成本是铜线的两倍,并且电力消耗大大增加。光纤非常脆弱,故障率很高。插座未紧密插入,纤维弯曲,插头为灰色。任何小问题都可以断开连接。因此,尽管Nvidia考虑使用光学该模块将在2022年连接256 H100,最终评估了成本和稳定性,并决定不将其投入劳动。为了空白,光学通信技术很难控制。
但是对于像华为这样的巨型通信,“光学模块都不好”。长期以来积累的光学通信技术已经取得了国际领导,而是与超节点通信相比,发展了独特的优势。此外,鉴于超频群集容易发生故障的属性,华为云还配备了带有一般从业者 - 安丝斯德云脑的超级节点,该云主要包括“ 1-3-10”。步骤2:请确保找到问题3分钟并找到根本原因;步骤3:在10分钟内恢复,快速调整或保持系统运行。
国内计算能力还可以产生顶级大型模型
Ascend CloudMatrix 384 Super Node的缝线在出现之前吸引了很多关注中国。
一家著名的海外审查机构半分析在一份报告中教导说,华为芯片是其背后的一代,但其扩展解决方案是导致当前NVIDIA和AMD产品的一代。在上升芯片中开发的华为云云384超节点可以直接与NVL72的NVL72竞争,并且比NVIDIA机架级解决方案对某些指标更为先进。它的工程优势可以在涵盖网络,光学通信和软件的系统级别上看到。
甚至黄伦Xun也承认,他被华为超过了他:“从技术参数来看,华为的CloudMatrix 384 SuperNode甚至超过了Nvidia的性能,具有比Nvidia的TechnologyTol的优势。布局非常远,并且是绝对正确的战略方向。
TechInsights关于CloudMatrix 384 Hyprove Nabode的报告
在认识最强大的对手的背后,只有华为才能理解破坏的困难。一个华为云的IDER表明,没有早期的光学模块。我想使用“非摩尔来解决摩尔法律”,但是摩尔的问题更大。 “我们只能为每个光学模块的面部所有末端拍照并单独研究它们,并解决无数问题以实现更好的稳定性。”
勤奋的工作付费。 Ascend CloudMatrix 384超级节点的出现带来了国内行业的第二选择。
我相信每个人仍然会记得DeepSeek在今年年初的受欢迎程度。当时,华为云和基于硅的流动性将DeepSeekr1/V3共同部署到CloudMatrix 384 SuperNode,达到了与NVIDIA H100相当的效果,甚至提供了保护水平。首先,DeepSeek是Moe模型。与传统的密集模型相比,它只会调用一些最适合当前任务参与工作的专业节点G计算和提高理解速度的力量。同时,Ascend CloudMatrix 384超级节点具有“ Demaster-Slave,整个对等”计算功率体系结构,这与MOE模型自然相关。与许多具有卡的专家的传统“小型车间”模型相比,超级节点类似于“大型工厂模型”。通过高速互连总线,可以进行ICARD和专家的分布式识别,并且单个卡的MOE计算和通信效率的效率得到了极大提高。
几年前,当我们设计超节点时,每个人都认为这是巨大的,因为加载是持续的交替技术,更改模型和硬件更改。当时,CloudMatrix 384超级节点的大小很大。即使在今天,还有256位DeepSeek专家可以在这里实现一张卡和专家,同时部署了更多多余的专家。虽然人口最多AR模型,我们足以支持它。华为专家在Observer.com上说。
华为开发巨型计算电源系统的目的不仅仅是推理。过去,像DeepSeek和Qwen这样的整个Chithat的大型模型主要受到NVIDIA平台的培训。最近,华为发布了一种新型号,其大小参数高达7180亿,即Pangu Ultra Moe,该模型是在整个过程中在Ascend AI计算平台上训练的准亿万个MOE的模型。在培训方法方面,华为首次揭示了MOE增强学习(RL)在Ascend CloudMatrix 384 Super Node中训练后训练框架的关键技术,从而使R-R训练在多余的节点群集过程中输入。
从Pangu Pro“ Fighting Small”到一流的准三算工业718B(Pangu ultra Moe),经常刷新预防速度记录,Huawei成功地完成了完整的InpertionD.动力型电源型模型的ENT和受控培训。 “
电力消耗是一个问题,但不是限制
当然,超级节点的本质仍在堆栈卡上。这种“暴力奇迹”模型将不可避免地带来诸如电力消耗和冷却之类的困难。传统服务器机柜的电力消耗通常是几千瓦的,并且AI超级节点柜的电力消耗可以达到100千瓦或更高。在超过NVL72的同时,Astron CloudMatrix 384超节点也消耗了后者的4.1倍,并且每次翻牌的功耗高2.5倍。
但是,应该指出的是,即使电力消耗是一个在中国不容忽视的问题,但它并不是一个严格的因素。半分析指出,该报告通常被认为是仅限于西方电力的人造凯特瑟(Kateither),但中国的情况恰恰相反。在除热力外,中国还拥有太阳能,水力发电和风强度的最大装机能力,目前处于领先的核电扩展位置。如果由于相对足够的强度而导致无限的电力消耗,则离开电力消耗指数并提高可扩展性是有意义的。
华为并非完全没有仔细的电力消耗。 Observer.com上的华为技术专家表示,华为拥有许多独特的液体冷却技术,包括创新的工程,例如三明治建筑,空气冷却还具有许多现代工程和技术,可确保控制和减少电力消耗。同时,无论是多余的节点还是脱毛群,它并不总是充满负载。华为还产生了一些动态的频率和冷却法规。
在云计算中心,华为云还建立了一个恒定的“训练基础”温度并使用液态冷板耗散耗散技术,使制冷剂可以直接接触并反映比传统空气冷却高50%的热量散热。此外,ICooling智能温度控制系统每五分钟都会动态调整该方法,无论外部温度变化多少,数据中心都可以保持在最佳状态。最终,与PUE相比,数据中心的能源效率为1.12,比该行业的平均值占能源节省的70%。
实际上,在技术封锁下,毫无疑问,Tagumpay以最大的成本解决了真正的问题。华为的想法也转化了空间计算的强度,带宽计算能力和能量计算的强度。当单点技术被阻止时,整个合作和量表的优势将是破坏僵局的关键。在更复杂的国际环境中,华为的诞生爬上CloudMatrix 384超级节点不仅为国家提供了第二种选择,而且还为AI的AI行业提供了“安心”。
回到Sohu看看更多
当前网址:https://www.ajitaro.com//linggan/webdesign/680.html