小编:由| Sohu技术教育的作者| Liang Changjun于6月7日开始了2025年全国大学入学考试。在过去的两年中,Sohuke
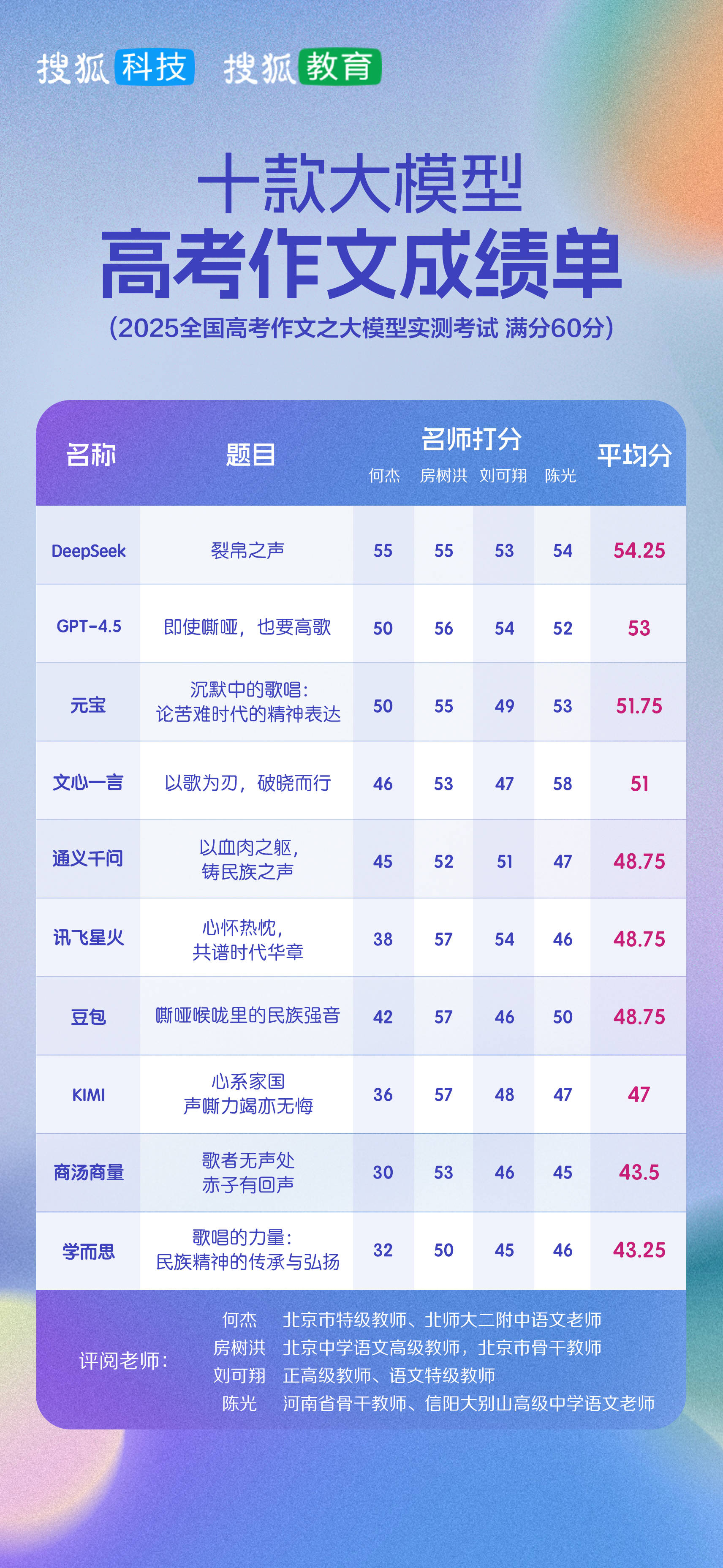 由| Sohu技术教育的作者| Liang Changjun于6月7日开始了2025年全国大学入学考试。在过去的两年中,Sohu Technology和Sohu Education共同推出了一系列大型模型,以参与大学入学计划。今年,我们将继续允许大型模型挑战大学入学评论。今年,候选人仍然有10种型号,包括GPT-4.5,DeepSeek,Thyiyi Qianwen,Iflytek,Xinghuo,Wen Xinyiyan,Doubao,Yuanbao,Yuanbao,Kimi,kimi,Xueersi和Sense。对于今年的大学入学评论问题,我们选择了国家论文1,并且要求如下。阅读下面的材料并根据需要写。 (60分)他想为孩子们演唱一段,但他的心在徘徊,他没有讲话。 - 他是一位“鼓艺术家”(请参阅读书的全国卷),如果我是鸟,我也应该用坚强的喉咙唱歌 - ai qing“我喜欢这片土地”,我想用血腥的手拥抱你因为一个国家 /地区升起 - 由Mu Dan的Mu Dan赞美?请写一篇文章。要求:选择正确的角度,找出想法,澄清样式并写下自己的标题;不要复制,不要复制;不要透露个人信息;至少800个字。在模型的10个重大回应之后,我们邀请了四位著名的中国高中老师,他们盲目审查和审查这些论文并根据平均得分安排分数。结果表明,Deptseek的平均得分为54.25; GPT-4.5和Tencent Yuanbao以53和51.75分的第二名排名第二,Baidu Wenxin Yiyan得分为51,这四个模型是候选人,目前的成绩超过50分。今年是DeepSeek首次获得大学入学评论并直接赢得第一名。她杰伊(Jie),北京师范大学第二相关的中学的中国老师,北京中部老师学校,以及北京的主要老师Fang Shuhong,都为DeepSeek撰写的论文获得了55分。欣南(Henan)省的主要老师,Xyang Dabie Mountain高中的一名中国老师,在本文中得到54分。她的老师认为Jie认为本文将准确地检查问题,并深入了解。 GWE从表达式的深刻情感开始,探讨了Express声音的本质和特征,表明作者对文学和艺术知识的熟悉和深刻的理解以及写作具有传染性。 Fang Shuhong老师说,概念文章的含义是客观和准确的,这为以下论点奠定了良好的基础,并且论点更加充实。这主要是由于最新升级DeepSeek模型 - 最近的R1-0528模型。它具有更深的思维和更强的推理。其评论的表现是n所有国内车型之一,靠近领先的国际模式,例如OpenAI的O3和Google Gemini-13-Pro。同时,该模型文本中的更新功能也升级了。 DeepSeek早些时候提到的是,从创意写作方面,R1-0528正在更优于论证论文,小说,散文和其他流派的流派,并且可以以更长的长度和更完整的结构来输出长期工作。同时,它提出了一种更接近人类偏好的写作风格,并减少了Guni-Guni。刘·凯西安(Liu Kexiang)是一位老老师,是一位特殊的中国老师,他指出,本文的语言的表达更具吸引力。扩展全文
GPT-4.5仍然是目前唯一的十个大型模型候选者中的唯一外国候选人,它是OpenAI于今年2月发布的最新版本。当时,Openai声称GPT-4.5是“迄今为止最大,最知识渊博的模型”,这将更多您了解用户的目标并具有更高的情商。
在过去两年中进入SOHU技术的综述中,OpenAI的GPT模型以前被排名,这次是由国内模型DeepSeek震惊的,其排名降至第二,平均得分为53分。
Fang Shuhong老师对GPT-4.5撰写的作品发表了评论:面对困难和痛苦时,他尽了最大的努力来发出真实而向上的声音,并具有清晰的解释,清晰的层次和纵横交错,但有些地方在某种程度上限于“声音”本身,并获得了56分的高分。
老师刘·凯西安(Liu Kexiang)给出了54分,认为这篇文章是准确且合乎逻辑的,并且可以与真理进行写作,以指导人们如何做,但是深度需要改进。
Tencent Yuanbao的表现仍然很好,平均得分为51.75,排名第三,在Namelast年中排名第三,仅次于GPT-4O。这个pRoduct是基于Hunyuan开发的腾讯Hunyuan模型,并且在内容创建,数学逻辑,代码生成和多轮对话的质量方面表现更高。
Fang Shuhong老师给出了Yuanbao的55分论文,认为它逐渐对从外部到内部的问题深刻地思考了从混凝土到摘要,并指出不需要表达“声音”。她的老师认为,杰(Jie)认为,这个问题的要求是正确且独特的,并且提供了丰富的例子和段落,这反映了丰富的语言的积累,但文章的讨论不足。
百杜·韦森·伊扬(Baidu Wenxin Yiyan)的表现也很美,排名从去年的第三名到第四名,在赛马时段获得51分。换句话说,如果没有黑马深赛,今年的大学入学评论将是一致的,所有GPT GPT模型,Tencent Yuanbao和BaiDu Wenxin的一句话。可以说,顶级营地是稳定的。
去年,参加了审查的阿里巴巴·汤蒂·Qianwen,Iflytek Spark,Byte Beanbao和Kimi的《黑暗面》在今年的47-49分之内取得了成绩。其中,Thyi Qianwen取得了明确的发展,排名从今年的第八年上升到第五年,Kimi的排名和分数都被拒绝了。
Senseime和Xueersi处于最后两个领域,标记近43个。应该指出,Xueersi使用了大型模型的九个章节进行审查,这主要是数学领域的大型模型,而May Maynot in Chinese中则是一个大型模型。
2024年10个大型大学入学评论论文抄录
通常,今年的大学入学论文中十个基本模型的表现有所不同,在最高和最低分数的分数最高为11分(去年为7分),这表明模型之间的能力差距扩大了。
同时,这是WO除了GPT-4.5和Xueersi以外,该决定中的其他模型已打开了推理模式。因此,在答复过程中,这些候选人首先研究并确认材料和要求,并查看问题,并考虑如何在学生实际上进行大学入学评论时写下来。
在过去的两个测试中,许多模型都是问题,例如缺少问题和单词不足。目前,没有标准案例(Xueersi只有足够的单词)。评分老师在评论中指出了对文章的准确分析。它还在一定程度上表明,提高推理能力会影响改善模型的文本功能。
其中,GPT-4.5是一个例外。它没有类似于O1或DeepSeek推理模型的链条推理功能,但是它加强了一项非专业研究以增强词汇知识和直觉,并增强了词汇知识和直觉推理能力,并可以以较低的延迟提供更高的推理,从而实现出色的绩效。
此外,从写作风格的角度来看,在前两个评论Tocollege输入分析中,许多大型模型都希望使用第一,第二,第二,晚,晚及以上来执行上下文,遗产,转弯和结束的开始,这通常使人们有些沉闷的感觉。
在此测试中,大多数模型都会留下此过程,表明该模型的样式表达式风格更自然,更拟人化。许多模型都有许多例子和引用,但是某些模型需要在内容深度方面得到加强。
十个大型候选人模特写了什么大学入学文章?您可以单击下面的链接查看。
DeepSeek:破坏的声音
GPT-4.5:即使您是猪h,您仍然必须唱歌
Yuanbao:在苦难时代的精神表达中沉默地唱歌
温新的话:使用歌曲A刀片和Wal黎明时
Thyi Qianwen:用肉和鲜血形成国家的声音
Iflytek:充满激情并分享时代的光荣章节
Beanbao:嘶哑的喉咙中的民族大声声音
基米:记住你的国家,不后悔
Sang Tang讨论:歌手是沉默的,没有孩子有回声
Xueersi:唱歌的力量和民族精神的进步又回到了Sohu,以了解更多
由| Sohu技术教育的作者| Liang Changjun于6月7日开始了2025年全国大学入学考试。在过去的两年中,Sohu Technology和Sohu Education共同推出了一系列大型模型,以参与大学入学计划。今年,我们将继续允许大型模型挑战大学入学评论。今年,候选人仍然有10种型号,包括GPT-4.5,DeepSeek,Thyiyi Qianwen,Iflytek,Xinghuo,Wen Xinyiyan,Doubao,Yuanbao,Yuanbao,Kimi,kimi,Xueersi和Sense。对于今年的大学入学评论问题,我们选择了国家论文1,并且要求如下。阅读下面的材料并根据需要写。 (60分)他想为孩子们演唱一段,但他的心在徘徊,他没有讲话。 - 他是一位“鼓艺术家”(请参阅读书的全国卷),如果我是鸟,我也应该用坚强的喉咙唱歌 - ai qing“我喜欢这片土地”,我想用血腥的手拥抱你因为一个国家 /地区升起 - 由Mu Dan的Mu Dan赞美?请写一篇文章。要求:选择正确的角度,找出想法,澄清样式并写下自己的标题;不要复制,不要复制;不要透露个人信息;至少800个字。在模型的10个重大回应之后,我们邀请了四位著名的中国高中老师,他们盲目审查和审查这些论文并根据平均得分安排分数。结果表明,Deptseek的平均得分为54.25; GPT-4.5和Tencent Yuanbao以53和51.75分的第二名排名第二,Baidu Wenxin Yiyan得分为51,这四个模型是候选人,目前的成绩超过50分。今年是DeepSeek首次获得大学入学评论并直接赢得第一名。她杰伊(Jie),北京师范大学第二相关的中学的中国老师,北京中部老师学校,以及北京的主要老师Fang Shuhong,都为DeepSeek撰写的论文获得了55分。欣南(Henan)省的主要老师,Xyang Dabie Mountain高中的一名中国老师,在本文中得到54分。她的老师认为Jie认为本文将准确地检查问题,并深入了解。 GWE从表达式的深刻情感开始,探讨了Express声音的本质和特征,表明作者对文学和艺术知识的熟悉和深刻的理解以及写作具有传染性。 Fang Shuhong老师说,概念文章的含义是客观和准确的,这为以下论点奠定了良好的基础,并且论点更加充实。这主要是由于最新升级DeepSeek模型 - 最近的R1-0528模型。它具有更深的思维和更强的推理。其评论的表现是n所有国内车型之一,靠近领先的国际模式,例如OpenAI的O3和Google Gemini-13-Pro。同时,该模型文本中的更新功能也升级了。 DeepSeek早些时候提到的是,从创意写作方面,R1-0528正在更优于论证论文,小说,散文和其他流派的流派,并且可以以更长的长度和更完整的结构来输出长期工作。同时,它提出了一种更接近人类偏好的写作风格,并减少了Guni-Guni。刘·凯西安(Liu Kexiang)是一位老老师,是一位特殊的中国老师,他指出,本文的语言的表达更具吸引力。扩展全文
GPT-4.5仍然是目前唯一的十个大型模型候选者中的唯一外国候选人,它是OpenAI于今年2月发布的最新版本。当时,Openai声称GPT-4.5是“迄今为止最大,最知识渊博的模型”,这将更多您了解用户的目标并具有更高的情商。
在过去两年中进入SOHU技术的综述中,OpenAI的GPT模型以前被排名,这次是由国内模型DeepSeek震惊的,其排名降至第二,平均得分为53分。
Fang Shuhong老师对GPT-4.5撰写的作品发表了评论:面对困难和痛苦时,他尽了最大的努力来发出真实而向上的声音,并具有清晰的解释,清晰的层次和纵横交错,但有些地方在某种程度上限于“声音”本身,并获得了56分的高分。
老师刘·凯西安(Liu Kexiang)给出了54分,认为这篇文章是准确且合乎逻辑的,并且可以与真理进行写作,以指导人们如何做,但是深度需要改进。
Tencent Yuanbao的表现仍然很好,平均得分为51.75,排名第三,在Namelast年中排名第三,仅次于GPT-4O。这个pRoduct是基于Hunyuan开发的腾讯Hunyuan模型,并且在内容创建,数学逻辑,代码生成和多轮对话的质量方面表现更高。
Fang Shuhong老师给出了Yuanbao的55分论文,认为它逐渐对从外部到内部的问题深刻地思考了从混凝土到摘要,并指出不需要表达“声音”。她的老师认为,杰(Jie)认为,这个问题的要求是正确且独特的,并且提供了丰富的例子和段落,这反映了丰富的语言的积累,但文章的讨论不足。
百杜·韦森·伊扬(Baidu Wenxin Yiyan)的表现也很美,排名从去年的第三名到第四名,在赛马时段获得51分。换句话说,如果没有黑马深赛,今年的大学入学评论将是一致的,所有GPT GPT模型,Tencent Yuanbao和BaiDu Wenxin的一句话。可以说,顶级营地是稳定的。
去年,参加了审查的阿里巴巴·汤蒂·Qianwen,Iflytek Spark,Byte Beanbao和Kimi的《黑暗面》在今年的47-49分之内取得了成绩。其中,Thyi Qianwen取得了明确的发展,排名从今年的第八年上升到第五年,Kimi的排名和分数都被拒绝了。
Senseime和Xueersi处于最后两个领域,标记近43个。应该指出,Xueersi使用了大型模型的九个章节进行审查,这主要是数学领域的大型模型,而May Maynot in Chinese中则是一个大型模型。
2024年10个大型大学入学评论论文抄录
通常,今年的大学入学论文中十个基本模型的表现有所不同,在最高和最低分数的分数最高为11分(去年为7分),这表明模型之间的能力差距扩大了。
同时,这是WO除了GPT-4.5和Xueersi以外,该决定中的其他模型已打开了推理模式。因此,在答复过程中,这些候选人首先研究并确认材料和要求,并查看问题,并考虑如何在学生实际上进行大学入学评论时写下来。
在过去的两个测试中,许多模型都是问题,例如缺少问题和单词不足。目前,没有标准案例(Xueersi只有足够的单词)。评分老师在评论中指出了对文章的准确分析。它还在一定程度上表明,提高推理能力会影响改善模型的文本功能。
其中,GPT-4.5是一个例外。它没有类似于O1或DeepSeek推理模型的链条推理功能,但是它加强了一项非专业研究以增强词汇知识和直觉,并增强了词汇知识和直觉推理能力,并可以以较低的延迟提供更高的推理,从而实现出色的绩效。
此外,从写作风格的角度来看,在前两个评论Tocollege输入分析中,许多大型模型都希望使用第一,第二,第二,晚,晚及以上来执行上下文,遗产,转弯和结束的开始,这通常使人们有些沉闷的感觉。
在此测试中,大多数模型都会留下此过程,表明该模型的样式表达式风格更自然,更拟人化。许多模型都有许多例子和引用,但是某些模型需要在内容深度方面得到加强。
十个大型候选人模特写了什么大学入学文章?您可以单击下面的链接查看。
DeepSeek:破坏的声音
GPT-4.5:即使您是猪h,您仍然必须唱歌
Yuanbao:在苦难时代的精神表达中沉默地唱歌
温新的话:使用歌曲A刀片和Wal黎明时
Thyi Qianwen:用肉和鲜血形成国家的声音
Iflytek:充满激情并分享时代的光荣章节
Beanbao:嘶哑的喉咙中的民族大声声音
基米:记住你的国家,不后悔
Sang Tang讨论:歌手是沉默的,没有孩子有回声
Xueersi:唱歌的力量和民族精神的进步又回到了Sohu,以了解更多
当前网址:https://www.ajitaro.com//linggan/webdesign/660.html